A Philosophical Audit of LLM-Generated Hypotheses: From Duhem–Quine to Scientific Discovery
This blog treats a recent perspective paper on LLMs in the scientific method as a subject for philosophical audit. Working through the Duhem-Quine thesis, Kuhnian paradigm theory, Lakatosian research programmes, reliabilism, the Gettier problem, and several other frameworks from philosophy of science and epistemology, it examines what these theses reveal about the epistemic status of LLM-generated hypotheses. The central argument is that the challenges facing LLMs in science are not primarily engineering challenges. They are constitutive philosophical ones, and they require a philosophy of AI-mediated science that the field has not yet developed.
1. Introduction: The Paper as a Starting Point
A recent perspective in npj Artificial Intelligence reviews how Large Language Models are reshaping the scientific method, from literature synthesis and experimental automation to hypothesis generation and open-ended discovery [1]. It identifies hallucination, reasoning fragility, and interpretability as serious obstacles. It proposes the useful concept of "algorithmic confidence" as a continuous trustworthiness measure. It advocates for human-in-the-loop throughout the scientific cycle.
And yet the paper implicitly assumes that the primary challenges are engineering challenges. Reduce hallucination, improve reasoning, increase interpretability, and LLMs will approach their potential as creative scientific engines. What the paper does not do, and what this blog attempts, is ask whether there are challenges that are deeper than engineering: challenges that are constitutive of what it means to generate, test, and evaluate a scientific hypothesis at all.
To do this, I will use the paper's own structure as a scaffold, passing each of its major sections through a set of philosophical theses that bear directly on the epistemology of LLM-generated hypotheses. The theses are not exotic. They are well-established positions in philosophy of science and epistemology that the AI-for-science community has largely not engaged with. My claim is that engaging with them changes what we should expect from LLMs, what we should fear about them, and how we should design the scientific workflows that incorporate them.
2. The Philosophical Toolkit
Before turning to the paper itself, it is worth assembling the philosophical instruments that will do the analytical work. Each addresses a different dimension of the problem.
The Duhem-Quine thesis holds that no hypothesis faces the tribunal of experience in isolation [2, 3]. Any test of a hypothesis also tests the background of auxiliary assumptions, measurement theories, and theoretical commitments that make the test possible. When an experiment fails, we cannot identify which element of the entire network is responsible for the failure. Confirmation and falsification are therefore holistic rather than atomistic operations.
Thomas Kuhn's analysis of scientific revolutions holds that scientists work within paradigms: shared frameworks of exemplars, assumptions, and problem-formulations that define what counts as a well-posed question and a satisfactory answer [4]. Normal science is paradigm-conserving; revolutionary science disrupts paradigms. The two modes require different cognitive stances and are not commensurable from within the paradigm undergoing disruption.
Imre Lakatos refined this picture by distinguishing the hard core of a research programme from its protective belt of auxiliary hypotheses [5]. Anomalies are absorbed by modifying the protective belt; the hard core is held constant by methodological decision. Research programmes are progressive when their modifications generate new predictions; they are degenerating when modifications are merely defensive.
Alvin Goldman's reliabilism holds that a belief constitutes knowledge only if it is produced by a reliable cognitive process, one that tends to produce true beliefs [6]. Reliability is not intrinsic to the belief; it is a property of the process that generated it, and it is domain-specific and empirically assessable.
The Gettier problem demonstrates that true, justified belief is insufficient for knowledge [7]. A belief can be true and produced by a reliable mechanism while still failing to constitute knowledge if the connection between the mechanism and the truth is accidental. Gettier cases reveal that the process-to-truth relationship must be appropriately non-accidental.
Ludwig Wittgenstein's rule-following considerations establish that no finite set of instances determines a unique rule [8]. When we say that a system is following a rule, we are making a claim that cannot be reduced to its observed behavior over any finite sample. A system can produce outputs consistent with a rule across all observed cases while following a different rule that diverges at the next case.
W.V.O. Quine's indeterminacy of translation holds that multiple incompatible translation manuals can fit all observable evidence equally well [3]. There is no fact of the matter that determines which translation is correct. Applied beyond natural languages, this principle challenges the assumption that we can uniquely determine the semantic content of a representational system from its observable input-output behavior.
The Strong Programme in the sociology of scientific knowledge, associated with David Bloor and Barry Barnes, holds that the content of scientific knowledge, not only its social acceptance, is shaped by social factors including the interests, values, and institutional structures of the communities that produce it [10].
Standpoint epistemology holds that the social position of a knower affects not only what they know but what they are epistemically positioned to know [13]. Marginalized standpoints sometimes afford epistemic advantages with respect to certain kinds of knowledge, particularly knowledge about social structures and their effects.
Finally, Herbert Simon's concept of bounded rationality and satisficing is relevant: agents do not optimize globally; they search until they find a solution that is good enough, given their computational and informational constraints [11]. The solutions they find are shaped by the structure of the search process as much as by the structure of the problem.
With this toolkit assembled, we can now turn to the paper.
3. LLMs as Scientific Copilots
The paper's first functional role for LLMs is the most modest and the most defensible: LLMs as copilots that summarize literature, extract structured data, annotate datasets, translate between domain vocabularies, and automate experimental design. These are genuine productivity contributions and the paper documents them carefully.
The Duhem-Quine problem enters at the level of relevance judgment. When an LLM-assisted literature search misses a paper or mischaracterizes a finding, we cannot determine whether the failure lies in the retrieval mechanism, the semantic embedding, the prompt framing, or the background assumptions the LLM uses to assess relevance. Every copilot output is bundled with an opaque auxiliary network. The paper acknowledges that prompting design critically shapes output. This is not merely an engineering observation; it is a manifestation of holism. The prompt is itself an auxiliary assumption, and its effects cannot be cleanly separated from the hypothesis or finding being sought.
Kuhn's theory-ladenness applies directly to the paper's optimistic claim that LLMs can "break down barriers of domain terminology" and facilitate interdisciplinary synthesis. LLMs do not access a theory-neutral vocabulary. They encode the dominant theoretical frameworks of whichever fields were best represented in their training data. When an LLM bridges genomics and chemistry, it does so through an inherited theoretical lens. The bridging is not neutral translation; it is theory-laden reframing. The synthesized interdisciplinary perspective carries the epistemic commitments of the training corpus.
The Strong Programme and standpoint epistemology converge on a structural concern that the paper raises but does not fully develop: LLMs trained predominantly on English-language, Western, peer-reviewed literature amplify the epistemic standpoint of a particular community rather than democratizing knowledge production. The paper notes this risk in passing and advocates for helping non-native English speakers communicate in the dominant scientific idiom. Standpoint epistemology would note that this is inclusion through linguistic assimilation rather than through epistemic pluralism, and that the two are not equivalent.
At the level of testimony epistemology, using an LLM as a scientific copilot is an act of deference to aggregated, compressed testimony. The classical conditions for rational testimony-based belief include knowing the speaker's competence, track record, and potential conflicts of interest. None of these conditions can be established for an LLM in any rigorous way. The paper's mitigation strategies, RAG grounding and human-in-the-loop review, are sound engineering responses. They do not resolve the deeper epistemic problem: we are extending epistemic trust to a source whose reliability conditions we cannot audit.
4. Foundation Models for Science
The paper's treatment of domain-specific foundation models, including Evo, scGPT, ChemBERT, and OmniJet-alpha, is among its most technically detailed sections. These models are presented as learning the "language" of scientific domains and achieving performance that approaches or exceeds human specialists on specific benchmarks. The paper is appropriately cautious about generalization beyond training regimes but frames the challenge primarily as a scaling question.
The Lakatosian framework reveals a structural problem with how these models are evaluated. When scGPT produces outputs that align with established biological knowledge, this is taken as evidence of validation. But scGPT was trained on the literature that established that knowledge. The apparent validation is not independent confirmation; it is the hard core of the training data reasserting itself. The protective belt of auxiliary hypotheses in the model absorbs anomalies; the hard core is never tested against genuinely independent evidence. This means that benchmark performance on in-distribution tasks systematically overstates the epistemic standing of model outputs.
Quine's indeterminacy of translation provides a further complication. When ChemBERT encodes SMILES strings and scGPT encodes single-cell data, they translate domain-specific symbolic systems into a shared representational space. Multiple incompatible translations could fit the observable input-output behavior equally well. High benchmark performance underdetermines semantic fidelity. A model can achieve excellent scores while systematically misrepresenting the underlying structure of the domain it purports to have learned.
Wittgenstein's rule-following considerations make this precise. When Evo performs zero-shot function prediction across DNA, RNA, and protein modalities, it has inferred some generalization from its training examples. But which generalization? No finite set of test cases can establish that the model is following the right rule rather than a rule that coincides with the right one on the test distribution and diverges elsewhere. The paper's enthusiasm about emergent capabilities does not address this, because emergence is identified through benchmark performance, and benchmark performance is exactly the evidence Wittgenstein's analysis shows to be insufficient.
The Gettier problem surfaces in the paper's discussion of AlphaProof achieving mathematical capabilities comparable to IMO competitors. Proving a theorem via reinforcement learning against a formal verifier is obtaining true, verified output through a process that is systematically disconnected from mathematical understanding as philosophers and mathematicians have analyzed it. The output is correct; the process is reliable within its formal domain; yet it remains an open question whether any of this constitutes mathematical knowledge in any richer sense. The paper does not distinguish between solving and understanding, and this distinction matters enormously for whether foundation models can drive fundamental scientific discovery rather than execute well-defined formal tasks.
Simon's bounded rationality is also relevant here. The scaling law enthusiasm in the paper implicitly assumes that more parameters, more data, and more compute reliably produce better science. But models satisfice within the constraints of their training objective, and the training objective, next-token prediction or its variants, is not aligned with scientific discovery as a goal. Larger models satisfice better within the objective they were trained on. Whether that objective is the right one for science is a question that scaling alone cannot answer.
5. LLMs as Creative Engines: The Hypothesis Generation Problem
The creative engine aspiration is where the paper is most ambitious and where the philosophical difficulties are most severe. The central claim is that LLMs can generate novel scientific hypotheses, recombine existing knowledge in productive ways, and potentially expand the frontier of what human scientists would consider. The paper frames this within a broadly Popperian model of science: propose hypothesis, test experimentally, falsify or retain, repeat.
The Duhem-Quine thesis is most damaging here. Popper's model requires hypotheses that arrive as isolable, testable claims. LLM-generated hypotheses do not arrive this way. They arrive pre-embedded in the vast background of training data: its theoretical commitments, its empirical associations, its vocabulary and framing conventions. When such a hypothesis fails experimental testing, we face the full Duhemian problem. The failure might lie in the hypothesis itself, in the experimental design, in the LLM's auxiliary assumptions about domain causality, in the domain model used to interpret results, or in the prompt that framed the entire inquiry. The hypothesis-experiment-observation loop the paper describes cannot resolve this without radical transparency about background commitments that LLMs by design do not provide.
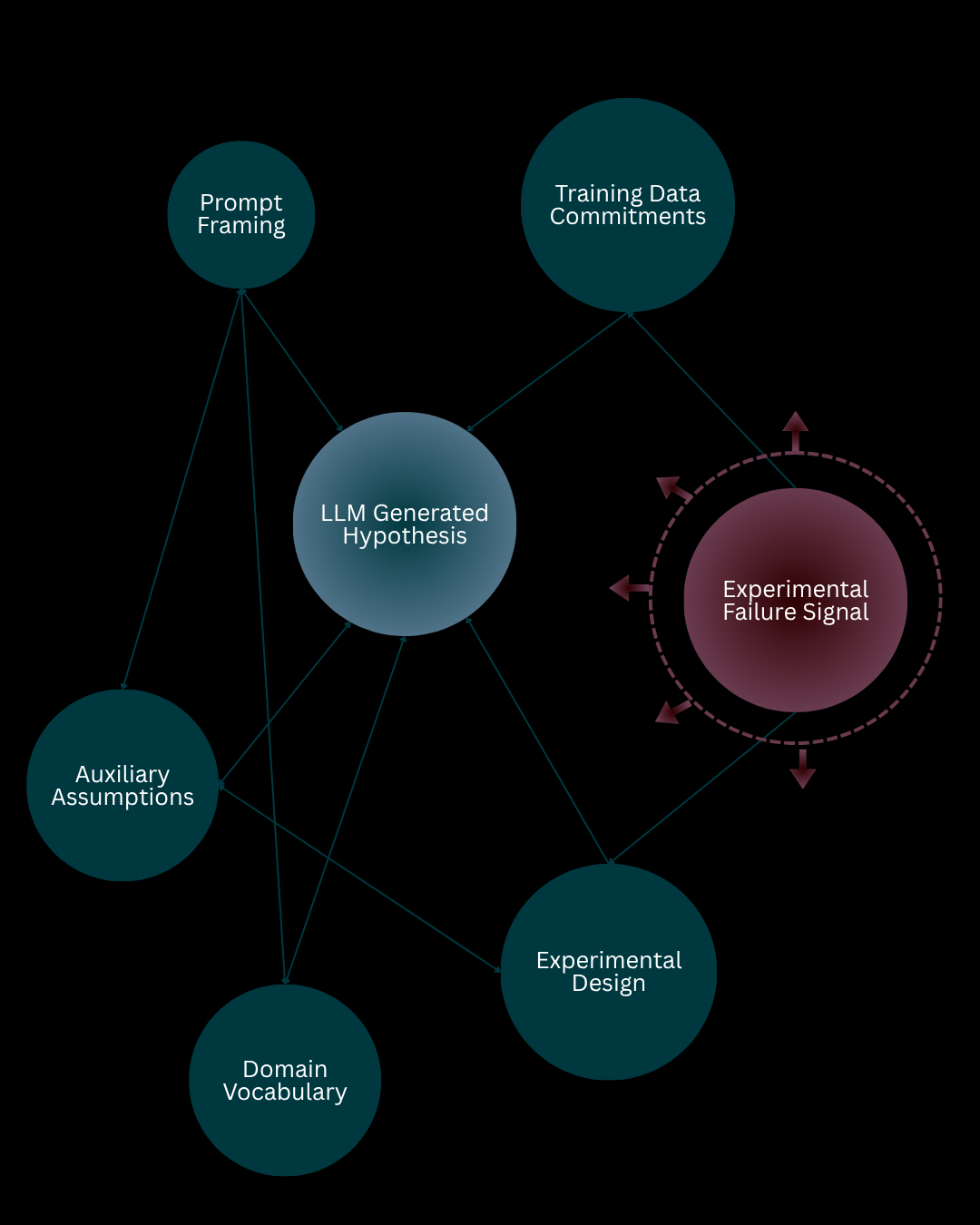
Figure 1: When an LLM-generated hypothesis meets experimental failure, the Duhem-Quine thesis tells us the failure signal cannot be cleanly attributed to the hypothesis alone. It distributes across the entire network: the prompt framing, the training data's theoretical commitments, the auxiliary assumptions baked into the model, and the experimental design. The Popperian loop — propose, test, falsify — assumes an isolable hypothesis. LLMs do not provide one.
Kuhn's analysis of paradigm-conservatism is equally troubling. LLMs are trained to produce outputs that are statistically consistent with their training corpus. The training corpus was produced within existing paradigms. Truly revolutionary hypotheses, those that challenge the hard core of an established research programme and inaugurate a new paradigm, are structurally underrepresented in any corpus produced by the paradigm they would disrupt. Paradigm-disruptive ideas, when they first appear, look wrong by the standards of the existing paradigm. An LLM trained to be coherent with existing science will be systematically biased against them. The paper's finding that LLM-generated ideas sometimes show lower novelty than human-generated ones is not a calibration problem to be fixed by better prompting. It is a structural consequence of what statistical coherence with a training corpus means.
Lakatos adds texture to this picture. LLM-generated hypotheses that seem novel may in practice function as modifications to the protective belt of existing research programmes rather than challenges to their hard cores. The appearance of novelty masks conservative epistemic structure. A hypothesis that recombines existing concepts in a new configuration is, in Lakatosian terms, still operating within the programme's protective belt. For an LLM to generate hypotheses that challenge a research programme's hard core, it would need to represent the hard core as explicitly revisable, which training on the programme's own literature makes unlikely.
Reliabilism demands a systematic audit of the hypothesis-generation process's track record across domains before we extend epistemic trust to its outputs. The paper offers domain-specific success stories, drug combination proposals for breast cancer treatment being the most compelling, but a single domain success does not establish domain-general reliability. More importantly, reliability is not just about accuracy; it is about accuracy for the right reasons. A process that generates plausible hypotheses by pattern-matching over a training corpus may be reliable within the training distribution and unreliable precisely where novelty matters most: at the boundaries of existing knowledge where the training distribution becomes sparse.
Paul Feyerabend's epistemic anarchism provides the paper's most unexpected ally [9]. His argument that scientific progress has historically required violating methodological norms, including the norm of consistency with existing theories, suggests that the proliferation of hypotheses, including implausible and even incoherent ones, is epistemically valuable because it prevents premature theoretical closure. The paper tentatively raises the possibility that hallucinations might serve as a mechanism for generating novel conjectures. Feyerabend would endorse this more strongly: let the LLMs generate freely, then subject the results to rigorous human adjudication. The difficulty is that the volume of LLM-generated hypotheses could overwhelm the adjudicative capacity of the scientific community, which is precisely the bottleneck that Feyerabend's framework does not address.
Kahneman's analysis of System 1 cognition is directly applicable here [12]. LLM hypothesis generation is fast, associative, and pattern-driven in ways that map almost exactly onto System 1. The known failure modes of System 1, availability bias, framing effects, anchoring, insensitivity to base rates, should therefore be expected in LLM outputs. When the paper notes that prompting design dramatically shapes which hypotheses emerge, this is a framing effect in the technical sense: the hypothesis space explored is not objective but anchored to the frame established by the prompt. The space of hypotheses that an LLM generates is therefore as much a reflection of the prompting strategy as of the underlying scientific problem.
6. Challenges: Hallucination, Reasoning, Transparency, and Community
The paper's challenges section is its most honest and philosophically aware. It correctly identifies reasoning limitations as severe, notes that self-correction often fails, documents the homogenization problem in LLM-assisted peer review, and proposes algorithmic confidence as a continuous trustworthiness measure. These are genuine contributions, and the section deserves credit for the nuance it brings to a literature that often oscillates between uncritical enthusiasm and dismissive skepticism.
The Gettier problem reframes the hallucination discussion in a philosophically important way. The paper treats hallucination as a bug: an output that is false but presented as true. The standard mitigations, RAG grounding, majority voting, chain-of-verification, are designed to increase the probability that outputs are true. But Gettier tells us that truth is not sufficient for knowledge. Even a true, RAG-grounded, majority-voted output fails to constitute knowledge if the process that produced it is not appropriately connected to the truth in the right way. An LLM can produce a correct scientific claim by a process of statistical pattern completion that does not track the causal structure that makes the claim true. This is not an exotic philosophical concern; it is a practical one for any context where the reliability of the truth-tracking process matters, which is to say, all of science.
Wittgenstein's analysis of rule-following clarifies why the paper's observation about unreliable self-explanation is deeper than an engineering limitation. The paper correctly notes that chain-of-thought explanations often do not reflect the actual computational process. This is not a calibration problem. A system that generates outputs by token prediction cannot report which rule it is following because rule-following, in the philosophically relevant sense, is not a state to which it has introspective access. Probing methods, the logit lens, representation engineering, dictionary learning, are external attempts to reconstruct the rule from behavioral evidence. But they face the same underdetermination problem that Wittgenstein identified: multiple rules are consistent with any finite behavioral sample.
The Strong Programme provides the most important framework for the paper's treatment of LLM-assisted peer review. The finding that LLM-assisted reviews assign systematically higher scores and produce homogenized critiques is not merely a quality-control problem. Peer review is the primary mechanism through which the scientific community adjudicates knowledge claims. Its epistemic function depends on the diversity of critical perspectives it aggregates: disagreement is informative, and the elimination of disagreement through homogenization degrades the information content of the review process. If LLMs systematically narrow the distribution of critical perspectives, they undermine the social epistemology of science at the community level. This is potentially more consequential than any individual hypothesis-generation failure, because it affects the institutional processes through which science self-corrects.
Standpoint epistemology creates a genuine tension in the paper's advocacy for LLMs as equalizers of scientific participation. The paper argues that LLMs can help non-native English speakers communicate more effectively, bridge disciplines, and access scientific knowledge that domain-specific vocabulary might otherwise wall off. All of this is true and valuable. But standpoint epistemology asks whether inclusion through assimilation to the dominant scientific idiom is the same as epistemic inclusion. A researcher who expresses their scientific thinking more fluently in the dominant idiom because of LLM assistance may be communicating more effectively while losing the distinctive epistemic contribution that comes from operating at the periphery of the dominant framework. The two forms of inclusion have different epistemic consequences for the scientific community.
7. Toward a Philosophy of AI-Mediated Science
Running the philosophical theses through the paper's structure reveals a consistent pattern. At each level, from copilot to creative engine, the paper correctly identifies a set of practical limitations and proposes engineering responses. What it does not do is recognize that many of these limitations are not engineering problems. They are instances of deep philosophical problems about the nature of knowledge, hypothesis, confirmation, and scientific community that have occupied philosophers of science for a century.
This matters for how we design AI-for-science systems and how we evaluate their outputs. If the primary challenges were engineering challenges, we could in principle solve them by improving models, better prompting strategies, more robust verification pipelines, and stronger human oversight. If the challenges are constitutive, they cannot be solved; they can only be managed, and managing them requires conceptual frameworks that engineering alone cannot provide.
Four constitutive challenges emerge from the audit.
The first is the opacity of auxiliary assumptions. LLM-generated hypotheses arrive pre-embedded in a theoretical network whose commitments cannot be made explicit through any currently available interpretability technique. This means that the Popperian hypothesis-test-falsify loop cannot function as designed, because the hypothesis is never truly isolated for testing. Managing this requires new practices of auxiliary assumption disclosure, analogous to the declaration of conflicts of interest, but at the level of theoretical commitments rather than financial ones.
The second is paradigm conservatism. Training-data-dependent systems are structurally biased toward the theoretical commitments of the communities that produced their training data. This is not a flaw to be corrected; it is a feature of how statistical learning works. Managing it requires deliberate attention to what kinds of hypotheses LLMs are unlikely to generate, and complementary methods for exploring the hypothesis space they systematically underweight.
The third is semantic underdetermination. The outputs of LLMs, including their generated hypotheses, are semantically underdetermined in ways that Quine and Wittgenstein identified precisely: multiple incompatible interpretations fit the observable behavior equally well, and there is no fact of the matter that selects among them. Managing this requires that LLM outputs be treated as prompts for human interpretive work rather than as claims with determinate semantic content.
The fourth is the social epistemology of AI-mediated science. LLMs affect not only individual scientific reasoning but the community-level processes through which science adjudicates knowledge claims. Homogenization of peer review, amplification of dominant-community perspectives, and the displacement of distinctive standpoints are changes to the epistemic infrastructure of science. Managing them requires governance frameworks that operate at the community level, not only at the level of individual model outputs.
The paper by Zhang, Khan, Mahmud, and colleagues is a valuable contribution to an important and rapidly developing literature. Its account of LLM capabilities and limitations is technically careful, and its advocacy for human-in-the-loop and algorithmic confidence is well-motivated. The philosophical audit proposed here is not a critique of the paper's technical claims. It is an argument that the field needs a layer of analysis beneath the technical one: a philosophy of AI-mediated science that can name the constitutive challenges, distinguish them from the engineering ones, and provide frameworks for managing what cannot be solved.
That philosophy does not yet exist in any systematic form. Building it is, arguably, the most important research programme that the AI-for-science community is not currently pursuing.
References
[1] Y. Zhang, S.A. Khan, A. Mahmud, H. Yang, A. Lavin, M. Levin, J. Frey, J. Dunnmon, J. Evans, A. Bundy, S. Dzeroski, J. Tegner, and H. Zenil. Exploring the role of large language models in the scientific method: from hypothesis to discovery. npj Artificial Intelligence, 1:14, 2025.
[2] P. Duhem. The Aim and Structure of Physical Theory. Princeton University Press, Princeton, 1954.
[3] W.V.O. Quine. Two dogmas of empiricism. The Philosophical Review, 60(1):20–43, 1951.
[4] T.S. Kuhn. The Structure of Scientific Revolutions. University of Chicago Press, Chicago, 1962.
[5] I. Lakatos. Falsification and the methodology of scientific research programmes. In I. Lakatos and A. Musgrave, editors, Criticism and the Growth of Knowledge, pages 91–196. Cambridge University Press, Cambridge, 1970.
[6] A.I. Goldman. What is justified belief? In G. Pappas, editor, Justification and Knowledge. D. Reidel, Dordrecht, 1979.
[7] E.L. Gettier. Is justified true belief knowledge? Analysis, 23(6):121–123, 1963.
[8] L. Wittgenstein. Philosophical Investigations. Blackwell, Oxford, 1953.
[9] P.K. Feyerabend. Against Method. New Left Books, London, 1975.
[10] D. Bloor. Knowledge and Social Imagery. Routledge, London, 1976.
[11] H.A. Simon. The Sciences of the Artificial. MIT Press, Cambridge, MA, 1969.
[12] D. Kahneman. Thinking, Fast and Slow. Farrar, Straus and Giroux, New York, 2011.
[13] S. Harding. The Science Question in Feminism. Cornell University Press, Ithaca, 1986.